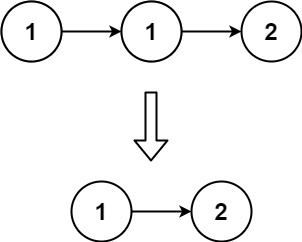
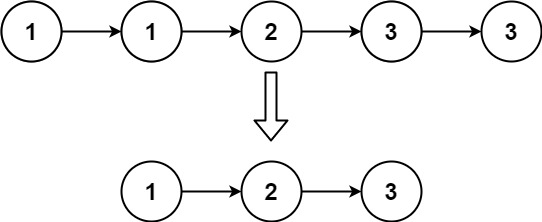
Given the head of a sorted linked list, delete all duplicates such that each element appears only once. Return the linked list sorted as well.
Example 1:
Input: head = [1,1,2]
Output: [1,2]
Example 2:
Input: head = [1,1,2,3,3]
Output: [1,2,3]
Constraints:
The number of nodes in the list is in the range [0, 300].
-100 <= Node.val <= 100
The list is guaranteed to be sorted in ascending order.
SolvingApproachs:
Approach 1: Straight-Forward Approach
Algorithm
This is a simple problem that merely tests your ability to manipulate
list node pointers. Because the input list is sorted, we can determine
if a node is a duplicate by comparing its value to the node after it in the list. If it is a duplicate, we change the next pointer of the current node so that it skips the next node and points directly to the one after the next node.
Complexity Analysis
Time complexity : O(n). Because each node in the list is checked exactly once to determine if it is a duplicate or not, the total run time is O(n), where n is the number of nodes in the list.
Space complexity : O(1). No additional space is used.
Correctness
We can prove the correctness of this code by defining a loop invariant.
A loop invariant is condition that is true before and after every
iteration of the loop. In this case, a loop invariant that helps us
prove correctness is this:
All nodes in the list up to the pointer current do not contain duplicate elements.
We can prove that this condition is indeed a loop invariant by induction. Before going into the loop, current points to the head of the list. Therefore, the part of the list up to current contains only the head. And so it can not contain any duplicate elements. Now suppose current is now pointing to some node in the list (but not the last element), and the part of the list up to current contains no duplicate elements. After another loop iteration, one of two things happen.
current.next was a duplicate of current. In this case, the duplicate node at current.next is deleted, and current stays pointing to the same node as before. Therefore, the condition still holds; there are still no duplicates up to current.
current.next was not a duplicate of current (and, because the list is sorted, current.next is also not a duplicate of any other element appearing beforecurrent). In this case, current moves forward one step to point to current.next. Therefore, the condition still holds; there are no duplicates up to current.
At the last iteration of the loop, current must point to the last element, because afterwards, current.next = null. Therefore, after the loop ends, all elements up to the last element do not contain duplicates.
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def deleteDuplicates(self, head: Optional[ListNode]) -> Optional[ListNode]:
if not head:
return head
node = head
s_head = ListNode(-111, node)
prev = s_head
while node:
if node.val == prev.val:
# remove it
prev.next = node.next
else:
prev = node
node = node.next
return s_head.next